
티스토리 뷰
배경
전 부하 테스트를 사용해 본 경험은 있지만 제대로 활용해 본 경험은 부족한 것 같습니다. 단순히 API를 하나씩 선정하여 부하를 주고, TPS가 어떤지 등만 확인하는 것에 불과합니다. 모니터링이 서버에 달려 있지만 어떤 지점을 파악해야 하는지 등에 대해서 전혀 무지합니다. 그래서 이번 기회에 문서화를 해보면서 어떻게 모니터링을 하는 것이 적절한지에 대해서 알아볼까 합니다.
(부하 테스트 및 모니터링 구축에 대한 내용은 포함하지 않습니다.)
환경
- VM: e2-small (vCPU 2개, 메모리 2GB), Ubuntu 22.04 LTS
- 서버 1대: Spring Boot 3.5, Kotlin, Java 17
- VM DB 1대: MySQL 8
- 캐시: Redis 싱글 인스턴스
- 모니터링: Grafana, Prometheus, Loki, Pinpoint
- 부하 테스트: nGrinder
테스트 툴은 nGrinder를 선택했습니다. 이전에 구축한 경험이 있기에 빠르게 구축이 가능하기 때문입니다. 또한 Java와 유사한 Groovy 문법을 사용해서 시나리오를 작성할 수 있고 GUI 툴을 제공한다는 장점도 있었습니다.
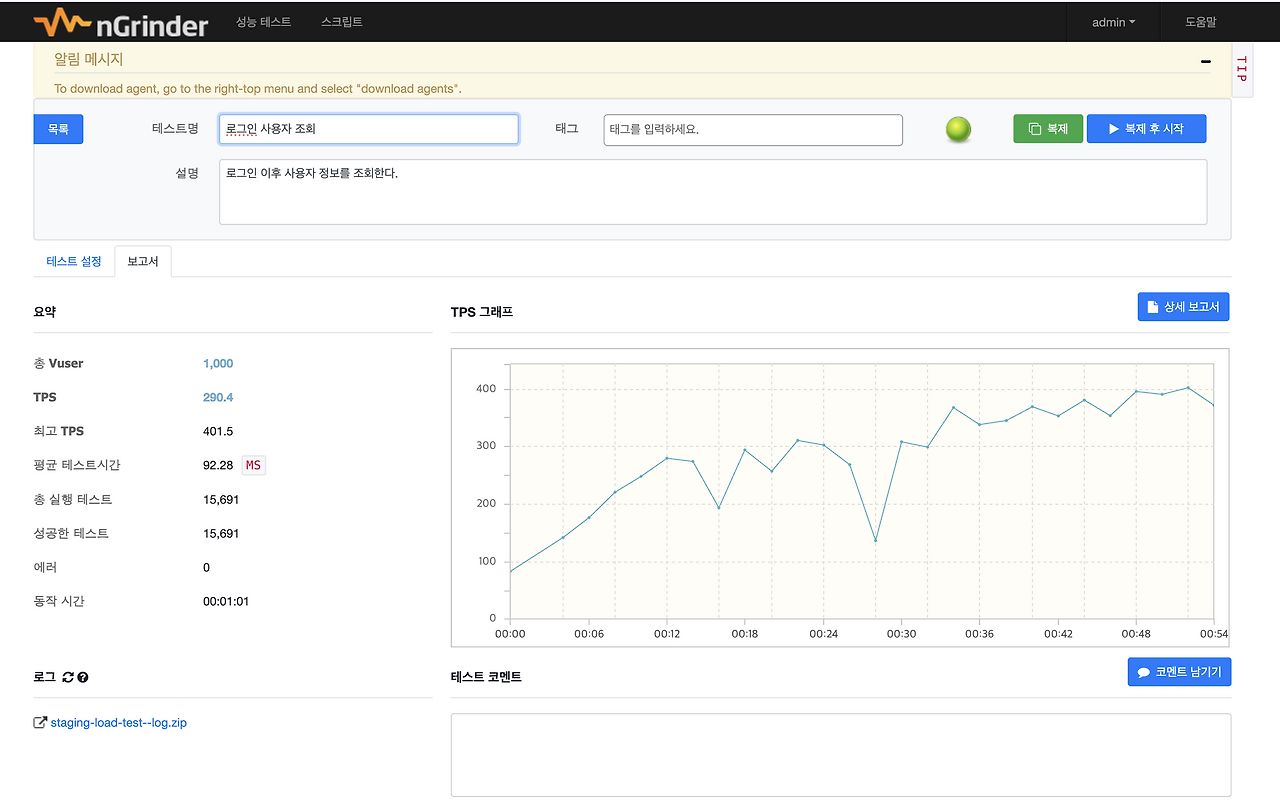
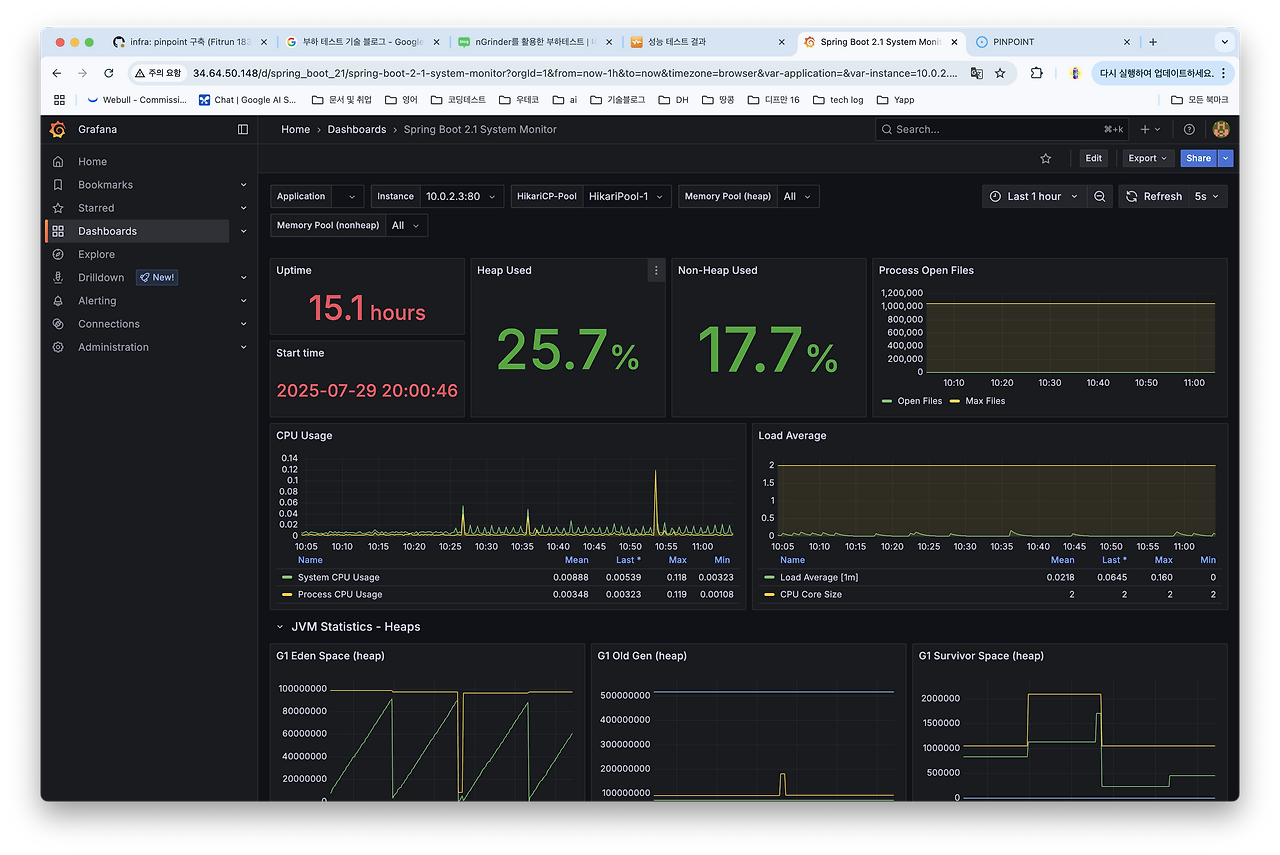
모니터링 툴은 Grafana & Prometheus를 통해 WAS를 모니터링 했습니다. 또한 병목 지점을 파악하기 위해 Pinpoint도 구축해 두었습니다.

목표
부하 테스트를 진행하기 앞서, 제가 어떤 것을 얻어갈 것인지에 대해 목표를 세워봤습니다.
- 현재 서버 구성으로 몇 명의 사용자를 수용할 수 있는가? 평균 TPS가 어느 정도 되는가?
- 서버 개발자로서 모니터링해야 하는 포인트가 어떤 것인지 체감하자.
- 병목 지점을 파악하고 개선할 수 있으면 개선하자 (최대 응답시간 2.5초 이내로)
- 서비스 코드에 문제는 없는지, 메모리 누수가 발생하거나 응답시간이 과도하게 지연되지 않는지도 확인하자
사용자 시나리오
부하 테스트를 진행하기 위해선 가상의 사용자가 어떠한 플로우로 저희 서비스를 이용할지 시나리오를 세우는 것이 선행되어야 한다고 생각했습니다. 그래서 저는 다음과 같이 시나리오를 만들었습니다.
참고로 저희 서비스는 ‘러닝 서비스’입니다.
- 사용자가 로그인 이후 홈 화면에 들어와 러닝 목표를 확인한다.
- 사용자가 로그인 이후 러닝을 달린다. 러닝 중간중간 오디오 피드백을 받는다.
- 러닝 이후 자신의 기록 리스트 및 세부 기록을 확인한다.
그리고 각 시나리오에 맞게 스크립트를 작성했습니다.
부하 테스트 진행
사용자 시나리오에 맞는 스크립트를 만들어두고 부하 테스트를 진행하였습니다. 부하 테스트에 앞서 신뢰성 있는 테스트를 위해 웜업 테스트를 사전에 진행했었습니다.
그리고 테스트에 사용할 시나리오를 만들었습니다. 첫 번째 시나리오는 사용자가 처음 저희 서비스를 이용하는 흐름으로 만들었습니다.
- 사용자가 소셜 로그인으로 로그인한다 (Save 쿼리 발생)
- 온보딩 과정을 진행한다(사용자 정보 입력, Save 쿼리 발생)
- 러닝 목표를 설정한다. (Save 쿼리 발생)
- 홈 화면 데이터를 조회한다.
그리고 부하 테스트를 진행했습니다.
무수한 에러와의 만남
저희 인프라는 모놀로틱으로 구성되어 있기 때문에 많은 사용자를 감당할 수 없을 것이라고 생각했습니다. 그래서 우선 10명의 동시 사용자를 가정하고 테스트를 진행하고 점차 늘려갔습니다.
그러다 20명의 동시 사용자 테스트에서 문제를 만나게 되었습니다. 테스트를 진행하고 나서 처음에는 잘 처리되더니 얼마 되지 않아 서버에 수많은 에러 로그가 쌓이고 있었습니다.

에러 내용은 다음과 같았습니다.
"Could not open JPA EntityManager for transaction"
트랜잭션을 여는 과정에서 시간이 초과한 것 같았습니다.
Pinpoint로 더 자세한 병목 지점을 확인할 수 있었습니다.

getConnection 메서드를 통해 커넥션을 획득하는 과정에서 30초를 초과하면서 타임아웃이 발생했고 이로 인해 에러가 발생하고 있었습니다.
Hikari CP의 커넥션 지표를 확인해 보면 대부분의 요청이 pending 상태로 유지되고 있었습니다.

별도의 커넥션 설정을 하지 않았기 때문에 커넥션 수는 기본값 10개로 되어있었습니다. 그런데, 20명의 부하 테스트를 진행했다고 10개의 커넥션이 고갈되는 문제가 발생한 것입니다. 테스트하는 API가 비즈니스 로직이 복잡하지 않고 복잡한 쿼리가 발생하는 API가 아니기에 이러한 커넥션 고갈 문제가 의아하게 느껴졌습니다.
APM을 통해 응답 시간 지표를 확인해 보았습니다. 처음에 정상적으로 처리되고 있는 로직들은 역시나 응답시간이 500ms를 넘지 않았습니다. 하지만 시간이 지나면서 10,000ms를 넘는 응답 시간을 보였습니다.

TPS도 70 정도를 유지하다가 갑자기 더 이상 요청을 처리하지 못했습니다.
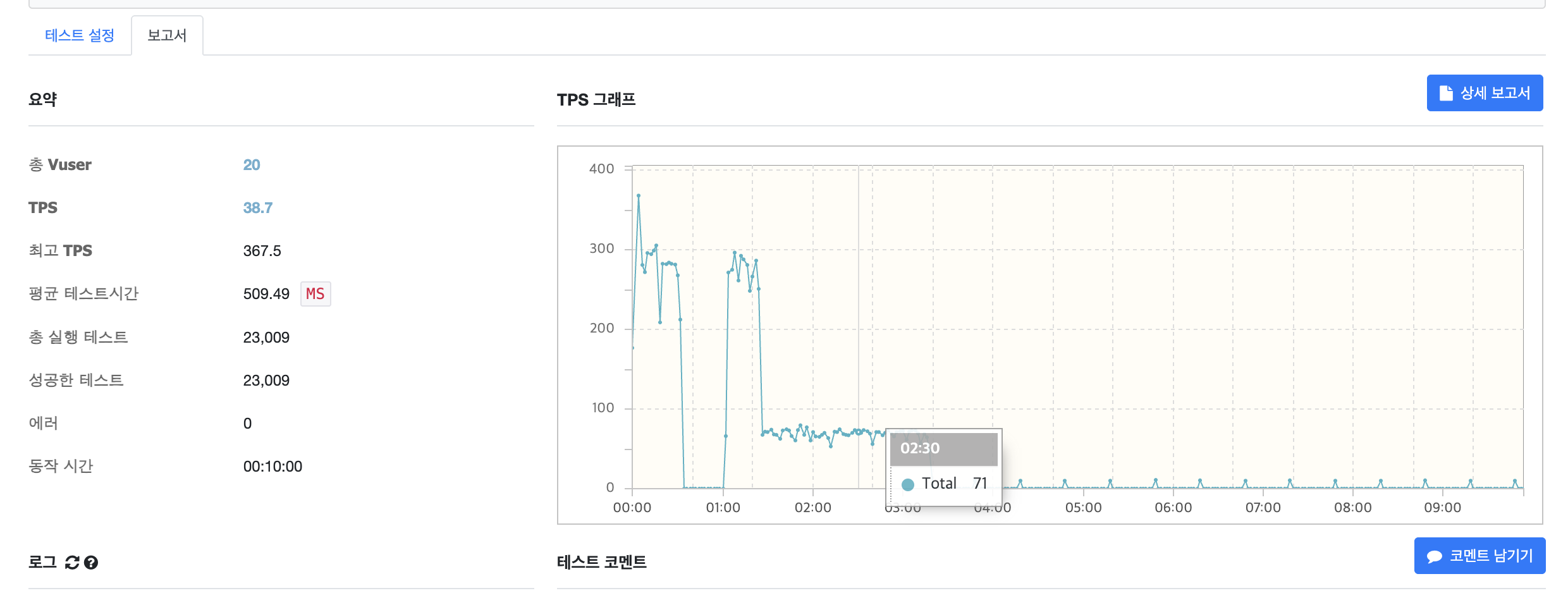
처음에는 커넥션을 반환하고 있지 않는 커넥션 누수를 의심했습니다. 하지만 만약 그렇기에는 처음에는 꽤 많은 요청이 제대로 처리되는 것이 납득이 되지 않았습니다. 만약 커넥션 누수가 발생하고 있다면, 커넥션 개수(10개) 만큼의 요청만 처리하고 이후에는 반환된 커넥션이 없기 때문에 전부 요청을 실패해야 합니다. 그러나 아래 사진과 같이 10개 이상의 요청들이 정상 처리되고 있었습니다.

원인 분석해 보기
원인을 찾기 위해 열심히 코드를 살펴보았습니다. 커넥션 획득과 관련된 DataSource를 프록시로 감싸서 로그를 찍어보았고 여기서 힌트를 얻었습니다.
import com.zaxxer.hikari.HikariConfig
import com.zaxxer.hikari.HikariDataSource
import org.springframework.boot.autoconfigure.jdbc.DataSourceProperties
import org.springframework.context.annotation.Bean
import org.springframework.context.annotation.Configuration
import org.springframework.context.annotation.Primary
import javax.sql.DataSource
import java.sql.Connection
import java.sql.SQLException
@Configuration
class LoggingDataSourceConfig {
@Bean
fun rawDataSource(dataSourceProperties: DataSourceProperties): HikariDataSource {
val config = HikariConfig().apply {
jdbcUrl = dataSourceProperties.url
username = dataSourceProperties.username
password = dataSourceProperties.password
driverClassName = dataSourceProperties.driverClassName
maximumPoolSize = 10
minimumIdle = 10
connectionTimeout = 30000
}
return HikariDataSource(config)
}
@Bean
@Primary
fun dataSource(rawDataSource: HikariDataSource): DataSource {
return CustomLoggingDataSource(rawDataSource)
}
}
class CustomLoggingDataSource(private val delegate: DataSource) : DataSource by delegate {
@Throws(SQLException::class)
override fun getConnection(): Connection {
val c = delegate.connection
return LoggingConnection(c)
}
@Throws(SQLException::class)
override fun getConnection(username: String?, password: String?): Connection {
val c = delegate.getConnection(username, password)
return LoggingConnection(c)
}
}
class LoggingConnection(private val delegate: Connection) : Connection by delegate {
init {
val connId = Integer.toHexString(System.identityHashCode(delegate))
println("[CONN-$connId] acquired by thread=${Thread.currentThread().name}")
}
override fun close() {
val connId = Integer.toHexString(System.identityHashCode(delegate))
println("[CONN-$connId] returned by thread=${Thread.currentThread().name}")
delegate.close()
}
}이상하게 로그인 API에서 커넥션을 2개를 획득하는 것을 확인했습니다.

트랜잭션을 시작할 때 커넥션을 1개 획득하는 것은 이해가 되었습니다. 하지만 내부 로직을 수행하면서 커넥션을 추가로 하나 더 획득하는 것이었습니다. 좀 더 자세히 알기 위해 디버깅 모드로 내부 로직을 하나씩 호출하면서 커넥션을 어디서 더 획득하는지 확인해 보았습니다.

확인 결과 유저 정보를 저장하는 로직에서 커넥션을 새롭게 획득하고 있었습니다.
로그인 로직을 간단하게 표현하면 다음과 같습니다.
@Transactional
fun login() {
...
val isExiste = 유저 존재 여부 확인()
if (!isExiste) {
val newUser = User()
userRepository.save(newUser)
}
...
}바로 userRepository.save 가 호출되면서 커넥션을 새롭게 획득하고 있었습니다.
저는 JPA를 사용하고 있었기에 위 로직은 SimpleJpaRepository의 save로직을 통해 새로운 유저 엔티티를 저장합니다.

이 save 메서드에도 @Transcational 애노테이션이 달려 있긴 합니다. 하지만 propergate 옵션이 따로 설정되어 있지 않기에 기본 옵션인 REQUIRED 으로 기존 커넥션을 활용합니다.

(propergate 옵션에 대해 잘 모르시면 다음 글을 참고하시길 바랍니다. 여기선 단순히 새롭게 커넥션을 생성할지 말지 결정한다고만 이해하고 넘어가도 됩니다.)
그런데 왜 새로운 커넥션을 사용하고 있었을까요??
찾았다 진짜 범인
범인은 키 생성 규칙 때문이었습니다.
@Entity
@Table(name = "USERS")
class User(
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
val id: Long = 0L,
...
}부하 테스트 당시 User 도메인에서 키 생성 전략은 GenerationType.AUTO 였습니다.
Hibernate 5 부터는 GenerationType.AUTO 인 경우, 기본적으로 TABLE 전략을 사용하도록 바뀌었습니다. 그런데 이 TABLE 전략일 때, 커넥션을 하나 더 사용하게 되는 것입니다. (관련 Hibernate 자료)
코드로 확인해 보자
실제로 어떤지 디버깅 모드로 확인해 봤습니다.
디버깅 모드로 Hibernate의 StandardIdentifierGeneratorFactory 클래스에서 createIdentifierGenerator 메서드를 확인해 보면 어떤 키 생성 전략을 선택했는지 확인할 수 있었습니다.

id를 생성하는 identifierGeneratorFactory에서 getIdentifierGeneratorStrategy를 호출해 보면 SequnceStyleGenerator라는 객체가 키 생성 전략으로 들어가 있습니다.
SequenceStyleGenerator를 살펴보면 다음과 같았습니다.

Generates identifier values based on a sequence-style database structure. Variations range from actually using a sequence to using a table to mimic a sequence. (해석) 시퀀스 스타일의 데이터베이스 구조를 기반으로 식별자(ID) 값을 생성한다. 실제로 시퀀스를 사용하는 방식부터, 시퀀스를 흉내 내기 위해 테이블을 사용하는 방식까지 다양한 변형이 존재한다.
이 SequnceStyleGenerator는 데이터베이스가 시퀀스를 지원하는 경우에는 SEQUNCE 전략을 사용하고, 지원하지 않는 경우에는 시퀀스를 모방하기 위한 테이블을 사용하게 됩니다. MySQL에서는 SEQUNCE 전략을 제공하고 있지 않아서 TABLE 전략인 것이죠.
실제로 위 코드에서 더 깊게 들어가 보면 TableStructure라는 객체를 통해 테이블 기반으로 다음 키 값을 조회하는 로직이 있습니다. 여기서 키 값을 조회하기 위해서 delegateWork라는 메서드를 콜백과 함께 호출합니다.

이 delegateWork 메서드에서 커넥션을 얻은 뒤에 콜백을 수행하게 됩니다. 여기서 커넥션을 얻을 때 바로 NonContextualJdbcConnectionAccess가 사용되는 것을 볼 수 있습니다.

NonContextualJdbcConnectionAccess는 무엇일까요?? 커넥션 획득 방식에는 2가지가 있습니다.
- 현재 커넥션을 획득하는 ContextualJdbcConnectionAccess
- 새로운 커넥션을 획득하는 NonContextualJdbcConnectionAccess
NonContextualJdbcConnectionAccess는 현재 컨텍스트와 분리된 커넥션을 생성하는 방법으로 새롭게 커넥션을 사용하는 방식입니다. 바로 이 부분에서 커넥션을 추가로 가져오게 되면서 총 두 개의 커넥션을 사용하게 되는 것입니다.
커넥션을 추가로 사용하는 이유를 정리하면 다음과 같습니다.
- GeneratorStretegy.AUTO & MySQL 인 경우 Hibernate는 테이블을 통한 키 생성 전략인SequenceStyleGenerator를 선택한다.
- SequenceStyleGenerator는 내부에서 NonContextualJdbcConnectionAccess의 obtainConnection을 호출하여 새로운 커넥션을 가져온다.
- 새롭게 가져온 커넥션으로 테이블을 조회하여 키 값을 결정한다.
그래서 왜 에러가 난 거야??
커넥션을 2개나 사용한다는 것을 알았습니다. 그런데 그게 커넥션을 2개 사용하는 것이 왜 에러 발생의 원인이 된 걸까요? 2개를 사용해도 작업이 마무리하면 2개를 반납하니까 순차적으로 처리되어야 하는 게 아닐까요??
결론부터 말하면 커넥션 데드락 문제였습니다.
커넥션 풀에는 2 개의 커넥션(A, B)만 있다고 가정하겠습니다. 두 개의 로그인 요청이 동시에 오게 되면서 각 작업은 트랜잭션을 열기 위해 커넥션을 가져오게 됩니다. 요청 A는 커넥션 A, 요청 B는 커넥션 B를 가져갔습니다.

획득한 커넥션으로 트랜잭션이 시작되고 로직이 수행됩니다. 그러다가 키 생성 전략이 TABLE이기에 새롭게 커넥션을 획득을 시도합니다. 하지만 이때, 커넥션 풀에 남아있는 커넥션이 없습니다.
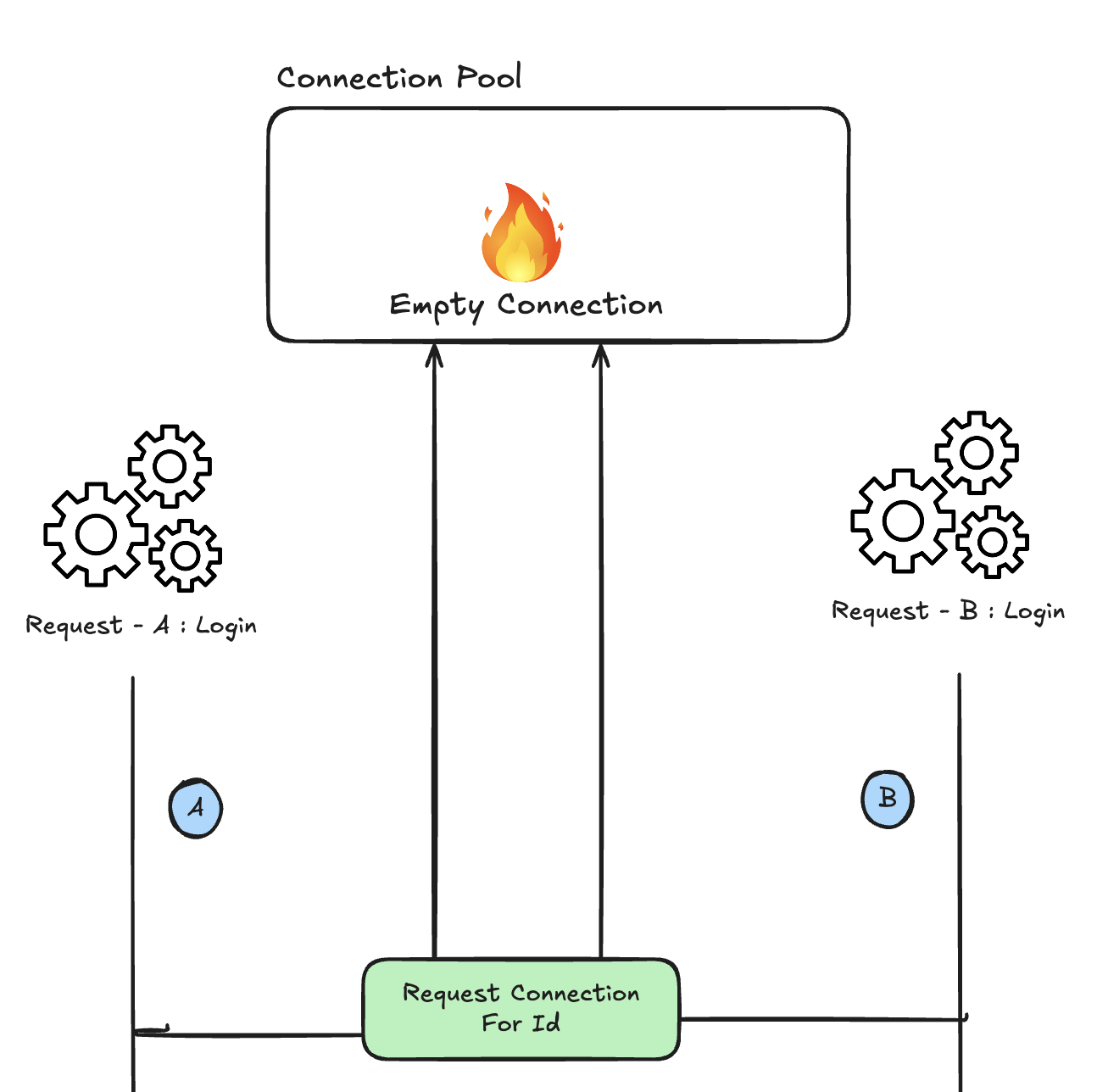
커넥션 풀에 남아있는 커넥션이 없으면 어떻게 처리될까요?? JdbcConnectionPool 클래스의 getConnection 메서드를 보면 자세히 나와있습니다.

Retrieves a connection from the connection pool. If maxConnections connections are already in use, the method waits until a connection becomes available or timeout seconds elapsed. (해석) 커넥션 풀에서 커넥션을 가져옵니다. 만약 maxConnections 개수만큼의 커넥션이 이미 사용 중이라면, 이 메서드는 커넥션이 사용 가능해질 때까지 또는 timeout 초가 지날 때까지 대기합니다.
더 이상 가져올 커넥션이 없다면 timeout시간이 초과할 때까지 반복문을 돌면서 반납되는 커넥션이 있는지 확인하게 됩니다. 그러다 시간이 초과되면 SQLException이 발생하게 되는 것이죠.
그렇기에 위 경우에도 두 개의 요청이 timeout시간까지 대기하다가 결국 예외를 터트리고 종료되게 됩니다.
테스트로 확인해 보자.
실제로 그럴지 테스트를 진행해 보았습니다.
우선 Hikari CP 커넥션 사이즈를 2로 설정합니다.
spring:
datasource:
hikari:
maximum-pool-size: 2
그리고 동시에 로그인 요청을 두 번 보내봐서 성공하는지 확인했습니다.
@Test
fun `동시에 로그인 두 번 하면 모두 성공해야 한다`() {
val callCount = 2
val startLatch = CountDownLatch(1)
val doneLatch = CountDownLatch(callCount)
val successCount = AtomicInteger()
val executor = Executors.newFixedThreadPool(callCount)
repeat(callCount) {
executor.submit {
startLatch.await() // 동시에 시작
try {
authService.login()
successCount.incrementAndGet()
} catch (_: Exception) {
// 실패는 세지 않음 필요하면 여기서 로그 처리 또는 fail 처리
} finally {
doneLatch.countDown()
}
}
}
startLatch.countDown()
val finished = doneLatch.await(10, TimeUnit.SECONDS)
executor.shutdown()
assertThat(finished).isTrue()
assertThat(successCount.get()).isEqualTo(callCount)
}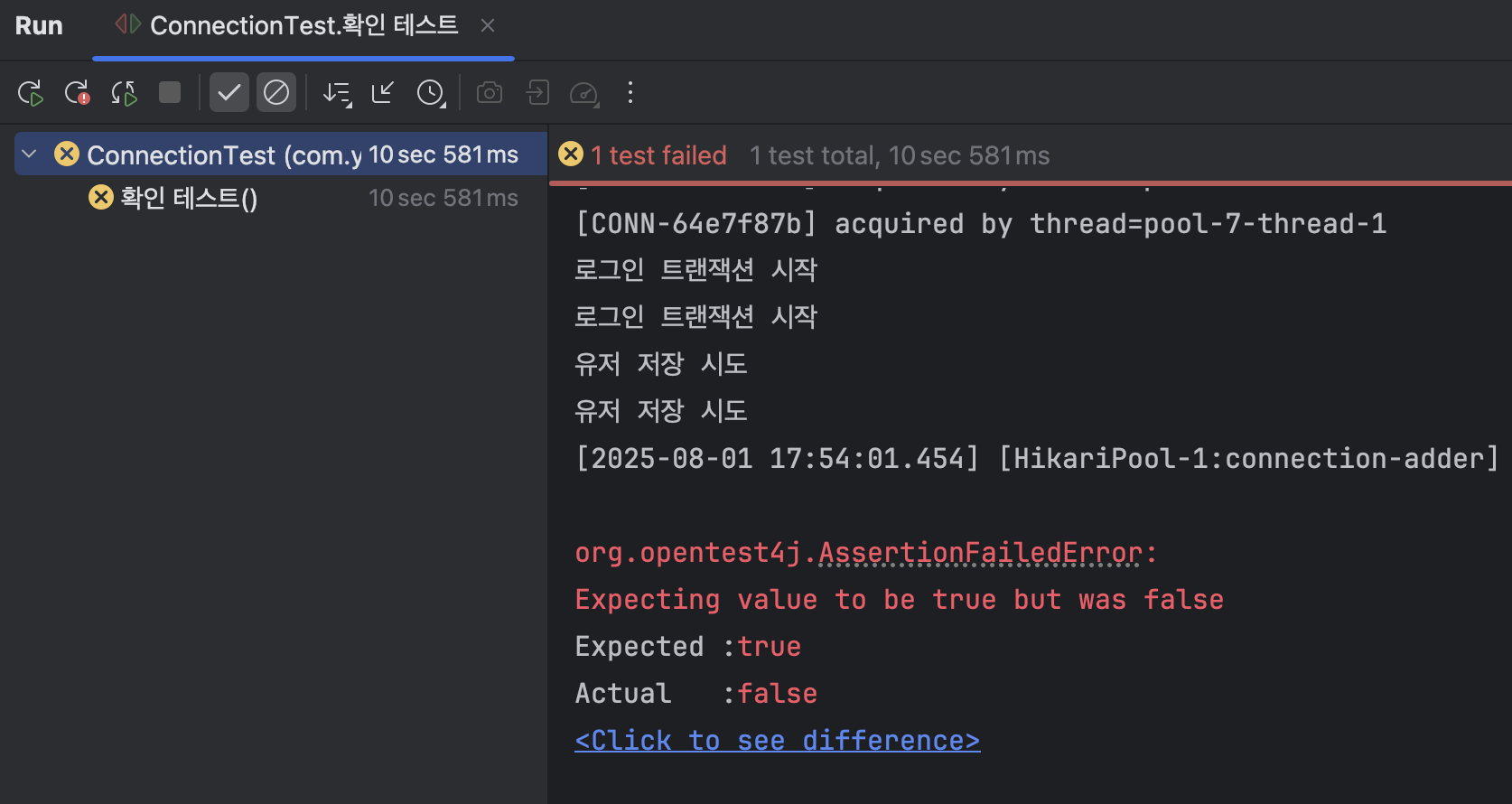
결과는 역시나 실패했습니다. 유저를 저장을 시도할 때 남아있는 커넥션이 없기에, 서로가 서로의 커넥션을 기다리고 이로 인해 데드락이 발생하게 됩니다.
어떻게 해결할까?
문제의 원인을 알게 되었습니다. 그러면 이제 어떻게 해결하면 될까요??
AUTO 사용 지양
우선 1차원적으로 GenerationType.AUTO 사용하지 않고 GenerationType.IDENTITY를 사용하면 해결할 수 있습니다. 그러면 커넥션을 하나만 사용하기 때문에 커넥션이 부족해질 가능성이 줄어들겠죠.
하지만 이는 근본적은 해결책이 될 순 없을 것 같았습니다. 당장의 문제는 GenerationType.AUTO를 사용했기 때문이지만, 나중에 다른 이유로 하나의 요청에 두 개 이상의 커넥션을 사용할 가능성을 완전히 배제할 순 없습니다. 트랜잭션 Propergation 옵션을 REQUIRE_NEW를 사용하게 되어도 커넥션을 두 개 이상 사용하게 되니까요. 따라서 똑같이 커넥션 데드락 문제가 발생할 수 있습니다.
적당한 커넥션 풀 사이즈
좀 더 근본적인 해결책은 적당한 커넥션 풀 사이즈를 설정하는 방법입니다. 커넥션 데드락이 발생한 이유는 모든 커넥션이 다른 커넥션 자원을 기다리기 때문에 발생하게 되었으니, 만약 커넥션이 여유가 있다면 요청을 제대로 처리할 수 있을 것이고 데드락 발생 가능성이 줄어들겠죠.
그렇다면 커넥션 풀 사이즈를 무조건 크게 만들면 괜찮을까요? 예상하시겠지만 당연히 그렇지는 않습니다. 커넥션 풀에 커넥션이 많다는 의미는 그만큼 리소스를 소비한다는 말입니다. 커넥션이 많다는 의미는 그 만큼 DB와 연결되어서 소비하고 있는 자원이 많다는 의미입니다. 너무 많으면 DB가 감당하지 못하고 전체 성능이 떨어지죠. 또한 커넥션 수만큼의 컨텍스 스위칭이 증가해서 CPU 효율이 떨어지죠.
그러면 얼마큼의 사이즈를 설정하는 게 적절한 커넥션 풀 사이즈일까요? 우아한 기술블로그를 통해 알게 된 사실이지만, PostgreSQL 기준으로 Hikari wiki에서 다음과 같은 공식대로 커넥션 풀 사이즈를 설정하면 데드락을 피할 수 있다고 합니다.
poolsize=Tn∗(Cm−1)+1
- Tn : 전체 Thread 개수
- Cm : 하나의 Task에서 동시에 필요한 Connection 수
https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing
이 공식을 50명의 동시 사용자일 경우를 가정하여 대입해 보겠습니다. 만약 50개의 동시 요청을 처리한다고 가정하고 각 요청이 커넥션을 두 개 사용한다면 50*(2 - 1) + 1 = 51개를 설정하면 데드락을 피할 수 있다는 것을 알 수 있습니다. 하지만 모든 요청이 커넥션을 두 개 이상 사용하는 것이 아니라 이 공식을 그대로 적용하기엔 어려움이 있습니다.
Hikari wiki에서는 또 다른 공식을 제공하는데 바로 CPU 코어 개수에 맞게 커넥션 수를 설정하는 공식입니다.
connections = ((core_count * 2) + effective_spindle_count)
effective_spindle_count 는 디스크 I/O 병목을 반영하는 값으로, 물리 스피너 개수입니다. 캐시 히트가 100%라면 0이 됩니다.
제 DB VM의 경우 cpu core는 1개였습니다.
effective_spindle_count 를 1이라 가정했을 때, 적절한 커넥션 수는 3개가 나옵니다.
정리하자면 다음과 같습니다.
|
기준
|
커넥션 수
|
|
CPU 코어에 맞는 커넥션 수
|
3
|
|
50명 동시 유저 데드락 회피 커넥션 수
|
51
|
새롭게 커넥션 수 설정하기
적절한 커넥션 수를 알게 되었습니다. 그러면 이제 다시 테스트해봐야 하죠.
저는 maximum-pool-size 수를 51로 설정하고, 유휴 상태 유지 커넥션 수를 설정하는 minimum-idle를 3으로 설정하였습니다.
spring:
datasource:
hikari:
maximum-pool-size: 51
minimum-idle: 3
idle-timeout: 30000이렇게 되면 기본적으로 DB CPU 코어에 맞는 커넥션 수가 생성되고, 이후 요청이 많아지면 커넥션 데드락을 방지할 수 있는 51개까지 커넥션을 생성하게 됩니다. 이를 통해서 적절한 커넥션 수를 유지하면서 데드락을 방지할 수 있습니다.
추가로 idle-timeout 값도 30초(30,000ms)로 설정해 주었습니다. idle-timeout는 커넥션 사용 후 재사용을 대비하여 유지되는 시간으로 기본값은 10분입니다. 만약 커넥션이 51개가 생성되었고 이후 요청이 줄었어도 10분 동안은 커넥션 51개가 유지되는 것입니다. 실제로 확인해 보니, Active 커넥션이 0개인데도 51개를 10분 동안 유지하고 있었습니다.
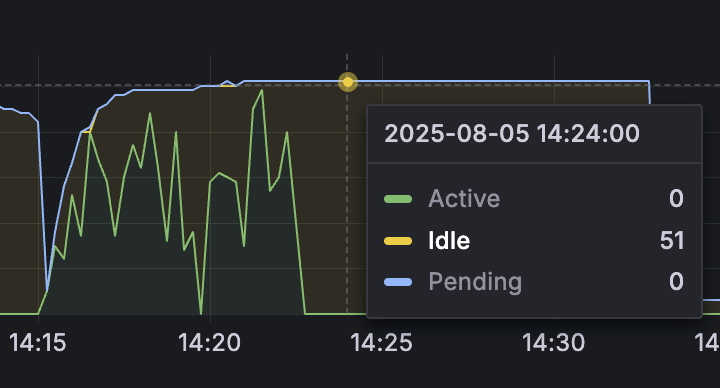
커넥션이 추가로 필요한 경우는, 데드락을 방지하기 위해 일시적으로 필요한 경우라고 생각했고 10분 이상 유지하는 것은 리소스 낭비라고 생각했습니다. 따라서 idle-timeout 값을 기존 10분에서 30초로 줄여주어 리소스 낭비를 방지했습니다.
부하 테스트 다시 진행
마지막으로 새롭게 바뀐 커넥션 수로 부하 테스트를 다시 진행해 보았습니다. 커넥션을 두 개 사용하는 경우에 대해 확인하기 위해 키 생성 전략은 그대로 AUTO를 유지한 상태로 부하 테스트를 진행했습니다.
똑같이 20명 동시 사용자 테스트를 진행했을 때 더 이상 에러가 발생하지 않는 것을 확인할 수 있었습니다.
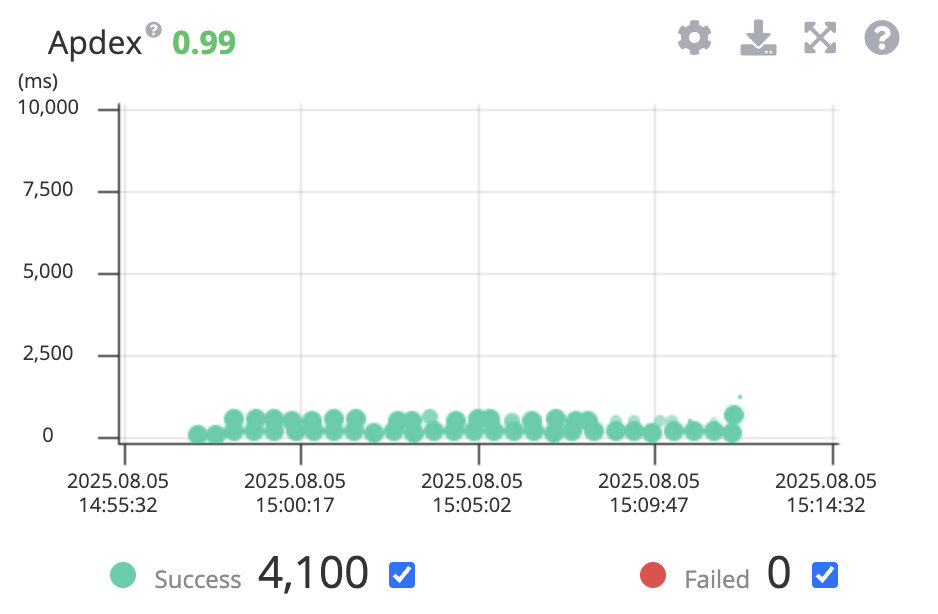
평균 TPS도 기존 70 정도에서 90 정도로 약 28.6% 개선되었습니다.

이렇게 커넥션 풀 문제를 해결하고 TPS 도 개선할 수 있었습니다.
APM과 모니터링 덕분에 문제를 빠르게 파악하고 개선할 수 있었던 경험이었습니다.
'개발 스토리' 카테고리의 다른 글
| 2025 토스 NEXT 백엔드 합격 후기 (10) | 2025.09.24 |
|---|---|
| 주기적으로 발생하는 API 지연 범인 찾기 (4) | 2025.08.15 |
| @Cacheable이 동작하지 않는 문제 해결기(AOP) (0) | 2025.07.18 |
| 문서화 툴 openapi3 + Stoplight 적용하기 (1) | 2025.07.15 |
| 요청 로그에 Body가 안나오는 문제 해결 (커스텀 Wrapper 도입) (3) | 2025.07.09 |
- Total
- Today
- Yesterday
- 파이썬
- 우아한테크코스 6기
- 알고리즘
- 토스 next 2025
- 우아한테크코스
- API 지연
- 코루틴
- 6기
- 커넥션 데드락
- 토스 2025 NEXT
- 게임개발
- 토스 합격 후기
- 우테코 6기
- 토스 백앤드 합격
- 우테코 프리코스
- JWT
- 자바
- 우아한테크코스 후기
- 분산락
- Cache Stampede
- 우테코 준비
- 우아한테크코스 자소서
- 레디스
- 캐시 스템피드
- 토스 NEXT 후기
- 토큰
- Assertions
- redis
- stoplight
- 우테코
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |